


Graph databases are a specialized category of database technologies that efficiently display, store, and query relationships between data objects. They use the concept of graph theory, structuring data as nodes (entities) and edges (relationships), each of which can potentially be decorated with properties to provide context. Graph databases differ significantly from traditional relational databases by offering a more intuitive structure for scenarios where relationships between data points are central to the information being processed.
Understanding graph databases is a powerful tool for data engineers and those who aspire to be data engineers. Graph databases enable direct modeling of relationships in networked applications such as social media, recommender systems, and logistics. This overview aims to uncover the essence of graph databases, highlighting their mechanics, benefits for specific use cases, and considerations for their implementation and integration into existing data architectures.
Understanding Graph Databases
The distinction between relational and graph databases is foundational, grounded in their divergent approaches to structuring and interpreting the connections within data. Relational databases arrange data into tables, a method that excels in handling structured data but often needs help with complexity when modeling dense interconnections. Graph databases, conversely, organize data as nodes and edges —entities and the relationships between them — equipped with properties and labels to enrich data with context and categorization.
Elements of Graph Databases
Nodes – represent the entities within the database, similar to rows in a relational table, but with the flexibility to encapsulate more complex and interconnected data.
Edges – serve as the connections between nodes, direct or indirect, illustrating the relationships that give graph databases their name and unique analytical power.
Properties – key-value pairs attached to both nodes and edges, providing a mechanism to store detailed information directly within the structure of the data itself.
Labels – categorization tools for nodes and edges, streamlining queries and analyses by grouping similar types of entities and relationships.
The contrast in data handling between relational and graph databases is stark. While relational systems rely on table joins to explore entity relationships — a process that can become cumbersome and slow with complexity — graph databases thrive in mapping out intricate networks of connections, allowing for swift and efficient data traversal.
Graph databases often employ specialized query languages tailored to navigate and manipulate their unique structure. For example, Neo4j utilizes Cypher, which is expressly designed for querying interconnected data.
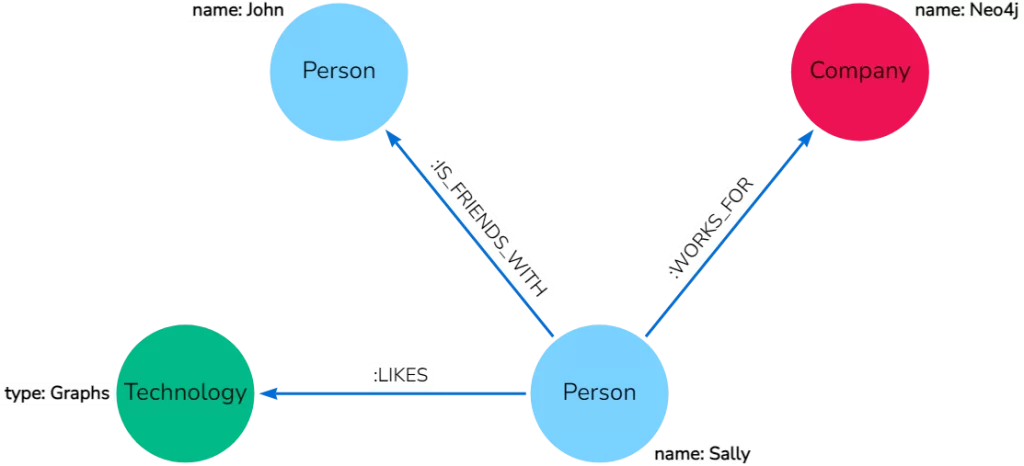
Query a Neo4j database using Cypher
These languages enable the formulation of queries that intuitively map to the graph structure, making the exploration of complex relationships both straightforward and powerful.
How Graph Databases Work
Graph databases operate on the principles of graph theory, embodying a sophisticated approach to data management that emphasizes the relationships between data points. At the heart of a graph database’s functionality are its core components — nodes, edges, properties, and labels — which together form a versatile framework for representing and querying complex datasets. This section delves into the mechanics of graph databases, elucidating how these elements coalesce to facilitate efficient data processing and retrieval.
Storage Mechanisms
Graph databases can be categorized based on their storage mechanisms: native graph processing systems and non-native graph processing systems. Native graph storage is designed explicitly for graph data, optimizing the storage of nodes, edges, and their associated properties to expedite traversal and query operations. Non-native systems, on the other hand, repurpose existing database technologies to store graph data, which can introduce inefficiencies in handling deeply connected data.
Native Graph Processing: In native graph databases, the physical storage layout mirrors the graph model, allowing for direct and efficient navigation of connections. This alignment significantly reduces the computational overhead associated with traversing relationships, making native graph databases particularly adept at exploring densely interconnected networks.
Non-Native Graph Processing: Non-native implementations store graph data atop relational or other types of databases. While they provide flexibility in leveraging existing database infrastructure, they may not offer the same level of performance for complex graph operations, especially in scenarios requiring extensive relationship traversals.
Graph Querying Languages
Graph databases typically come equipped with specialized querying languages designed to articulate graph-specific operations succinctly. These languages, such as Cypher for Neo4j, allow for expressive queries that intuitively align with the graph structure. They enable data engineers to specify patterns within the graph that match particular structures or relationships, facilitating the extraction of insights from the network of data entities.
Cypher – Neo4j Example:
Cypher is known for its declarative style, making it particularly accessible for expressing complex queries in a readable format. Let’s consider a more complex example involving pattern matching and aggregation:
MATCH (user:User)-[:PURCHASED]->(product:Product),
(product)-[:BELONGS_TO]->(category:Category {name: 'Electronics'})
RETURN user.name AS UserName, COUNT(product) AS NumOfElectronicsPurchased
This query identifies users who have purchased products in the “Electronics” category and calculates the total number of such products purchased by each user, showcasing Cypher’s ability to handle multi-step relationships and aggregation within a single query.
Gremlin – Apache TinkerPop Example
Gremlin offers a functional, data-flow style that excels in traversing graph structures. It is part of Apache TinkerPop, an open-source graph computing framework. Gremlin queries are built up step-by-step, allowing for precise control over the traversal process.
g.V().has('User', 'name', 'Alice')
.out('FRIEND')
.hasLabel('User')
.values('name')

In this Gremlin example, the query starts with a vertex representing a user named “Alice,” follows outgoing “FRIEND” relationships to other users, and then extracts the names of these friends. Gremlin’s step-by-step nature makes it highly flexible and powerful for detailed traversal specifications.
SPARQL – RDF Databases Example
SPARQL is used primarily with RDF (Resource Description Framework) databases, which are a type of graph database optimized for storing and querying metadata about resources. SPARQL is designed to query and manipulate RDF data.
SELECT ?friendName
WHERE {
?user rdf:type ex:User ;
ex:name "Alice" ;
ex:hasFriend ?friend .
?friend ex:name ?friendName .
}
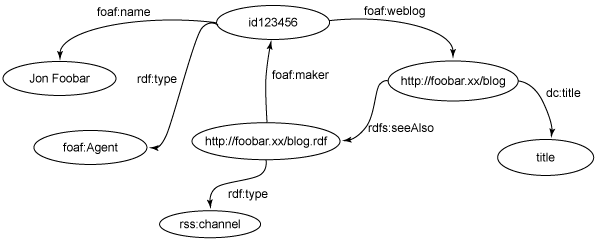
RDF data with SPARQL
This SPARQL query looks for users named “Alice,” identifies their friends, and retrieves those friends’ names. SPARQL’s pattern-matching capabilities make it well-suited for querying complex RDF data, which is often used in semantic web and linked data applications.
AQL – ArangoDB
ArangoDB uses AQL (ArangoDB Query Language), which is designed for flexibility, allowing queries on both document and graph models within the same database.
FOR user IN Users
FILTER user.name == "Alice"
FOR friend IN OUTBOUND user._id Friends
RETURN friend.name
This AQL query finds a user named “Alice,” traverses the “Friends” relationships to find her friends, and returns their names. AQL combines the document store’s querying capabilities with graph traversal operations, providing a multifaceted approach to data querying.
Indexing and Search Mechanisms
To enhance performance, especially in large datasets, graph databases implement indexing and search mechanisms. Indexes can be applied to properties of nodes and edges, enabling rapid lookup of entities based on those properties. Advanced graph databases also offer full-text search capabilities, further accelerating the retrieval of nodes and edges based on textual content.
By indexing key properties, such as a user’s name in a social network graph, the database can quickly navigate to specific nodes without scanning the entire graph. This capability is crucial for performance, ensuring that even as the dataset grows, queries remain fast and responsive.
Graph databases integrate these components and mechanisms to provide a robust platform for modeling and querying interconnected data. The choice between native and non-native storage, the use of graph-specific querying languages, and the implementation of efficient indexing and search strategies all contribute to the unique strengths of graph databases in handling complex, relationship-rich.