


The Role of Data Modeling in Data Engineering
Data modeling is the process of defining how data is stored, organized, and accessed within a system. It serves as the blueprint for databases, data warehouses, and data lakes, ensuring that data structures are clear, scalable, and aligned with the needs of the business.
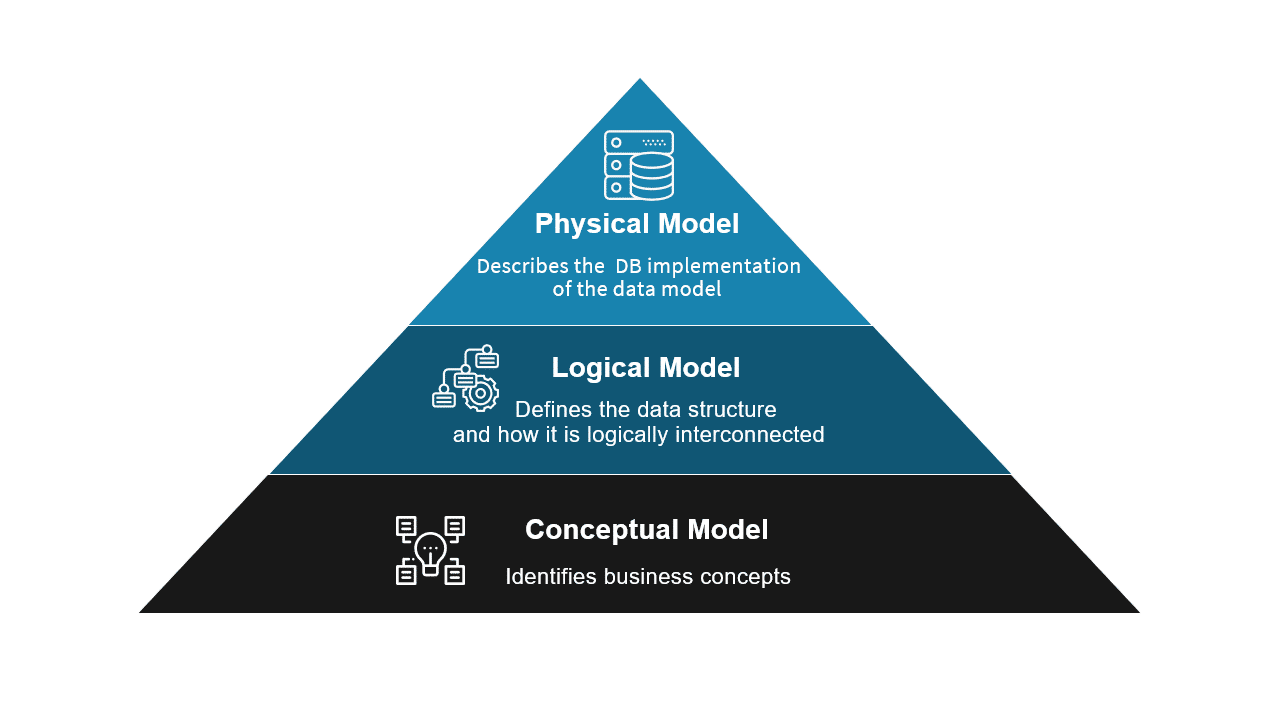
Data engineers translate raw, unstructured data into well-defined models that enable efficient storage and fast retrieval. This involves understanding the types of data models:
Conceptual models define the high-level structure of data based on business requirements.
Logical models detail relationships and attributes, often agnostic to any specific technology.
Physical models focus on the implementation, taking into account the constraints and capabilities of the underlying database or storage system.
By mastering these models, data engineers can design systems that are not only functional but also future-proof, supporting the evolving needs of the organization.
Organizations rely on robust data models to extract actionable insights in an increasingly data-driven world. Without a strong foundation in data modeling, data engineers risk creating systems that are inefficient, inflexible, or prone to errors. Key benefits of effective data modeling include:
A well-designed model ensures queries are efficient, reducing response times and computational costs.
Proper relationships and constraints prevent duplication, inconsistency, and data corruption.
Flexible models can accommodate future growth in data volume or complexity without requiring a complete redesign.
Models that reflect business processes enable stakeholders to derive meaningful insights quickly.
Theoretical knowledge is essential, but true expertise in data modeling comes from applying these concepts in real-world scenarios. The Data Engineer Academy course emphasizes practical learning, where you’ll:
Explore trade-offs like normalization versus denormalization in the context of actual use cases.
Learn how to optimize models for both OLAP (analytics) and OLTP (transactional) environments.
By the end of our programs, you will not only understand the principles of data modeling but also have the confidence to implement them in your work and communicate your decisions effectively to technical and non-technical stakeholders alike.
Investing in your understanding of data modeling is an investment in your career as a data engineer. With the right foundation, you’ll be equipped to design systems that deliver value, align with business needs, and scale effortlessly with technological advancements. Let’s continue exploring the best practices and tools that can make this possible.
Core Principles of Effective Data Modeling
When it comes to data modeling, it’s not just about creating structures to store data — it’s about building systems that are efficient, flexible, and able to grow with the needs of the business. By understanding the core principles of data modeling, data engineers can create systems that are both scalable and optimized for performance. Let’s explore these principles in detail.
1. Normalization
The normalization principle is all about organizing data to minimize the risk of inconsistency. Essentially, it involves breaking down data into smaller, more manageable units, ensuring that each information is stored only once. Doing so reduces storage requirements and makes it easier to maintain the data over time.
Normalization not only improves efficiency but also boosts performance. When data is stored more compactly and logically, queries can be executed faster, as the system doesn’t have to sift through duplicate or redundant data. This becomes particularly important as data volume increases.
Furthermore, normalization helps maintain data integrity. When updates or deletions are made, having data spread across multiple, logically related tables ensures that the system remains consistent and prevents anomalies such as orphaned records or conflicting data.
In practice, normalization is typically carried out in several stages, referred to as “normal forms.” As data engineers advance in their projects, they’ll often work to achieve higher normal forms, like Second Normal Form (2NF) or Third Normal Form (3NF), each of which eliminates different types of redundancy or dependency, ensuring that the database structure is both efficient and robust.
2. Data integrity
Closely tied to normalization is the principle of data integrity. Ensuring that data remains accurate, consistent, and reliable across the system is essential for any data-driven organization. When designing data models, data engineers must think about how data will interact within the system and set up appropriate constraints to prevent errors.
For example, primary keys and foreign keys play a critical role in preserving data integrity. A primary key uniquely identifies a record, ensuring there are no duplicates. Foreign keys establish relationships between different tables, helping to maintain consistency by ensuring that linked data remains valid. These constraints not only prevent data anomalies but also help maintain the overall structure of the system, making it easier to query and update data accurately.
Without proper data integrity rules, there’s a higher risk of introducing inconsistencies, which could lead to inaccurate insights or broken reports. This is why data engineers must think carefully about these relationships from the outset, ensuring that data is both accurate and consistent throughout its lifecycle.
3. Scalability
Another essential principle of data modeling is scalability. As businesses grow and data volumes increase, the systems built today must be able to handle that growth without performance degradation. The best data models are designed with future needs in mind, ensuring they can adapt as new data sources are added, business requirements evolve, and more complex queries are needed.
When designing scalable data models, data engineers need to consider how the structure will hold up under increasing loads. This may involve choosing the right storage systems, partitioning data effectively, or implementing indexing strategies to ensure that queries remain fast as data grows. The goal is to create a model that meets current requirements and accommodates future expansion—whether that means scaling up the infrastructure, supporting more data sources, or managing more complex relationships between data.
4. Adapting to changing business needs
Finally, flexibility is a core principle in data modeling. In today’s rapidly changing business environment, requirements can shift quickly, and systems must be able to adapt. A flexible data model allows for easy modifications and additions as new business needs arise. This is especially important in businesses that deal with diverse data sources or that need to iterate on new ideas quickly.
Flexible data models are often designed to be modular, so they can accommodate changes without requiring a full redesign. For example, when new data attributes or entities need to be added, a flexible model can integrate these changes smoothly without disrupting existing workflows or requiring extensive rework.
Practical Tips for Data Engineers
Creating effective data models requires a blend of theoretical knowledge, practical experience, and a solid understanding of the business context. As a data engineer, you are tasked with building models that meet the business’s immediate needs and scale efficiently over time. Here are some practical tips that can guide you through the process of data modeling, helping you design systems that are both powerful and maintainable:
1. Start with a clear business understanding
Before you begin designing any data model, it’s crucial to understand the business goals behind the project. Data engineering isn’t just about making data accessible; it’s about making data work for the organization. Have clear discussions with stakeholders to understand:
What are the core business processes?
How will the data be used? (e.g., for reporting, analytics, machine learning)
What are the scalability requirements?
By framing your data model around the needs of the business, you ensure that your design will meet both the immediate and future demands of the organization.
2. Prioritize simplicity and clarity in your schema design
While advanced modeling techniques are useful, the simpler and more intuitive the schema, the easier it will be to maintain. Stick to the principle of KISS (Keep It Simple, Stupid). Over-complicating the schema can lead to unnecessary complexity, which may hinder data retrieval and create maintenance headaches in the long run.
Avoid too many nested structures.
Focus on logical relationships.
Use clear and consistent naming conventions.
By focusing on simplicity, you make your model more understandable for future engineers and ensure that it’s easier to modify and extend as business needs evolve.
3. Plan for scalability from the start
One of the most important aspects of data modeling is planning for scalability. As data volumes grow, the systems that initially seemed adequate may start to falter. A model that is not designed with scalability in mind can lead to poor performance, increased latency, and challenges in data integration.
Think horizontally and vertically.
Consider how your model will handle large datasets or increasing data velocity.
Use partitioning, indexing, and sharding to optimize query performance and support horizontal scaling.
Scalability isn’t just a consideration; it should be baked into the design process from day one. Modular design, where components can be independently scaled, is key to managing growth efficiently.
4. Regularly review and refine your models
Data modeling is an iterative process. It’s essential to continuously review and refine your models as business requirements evolve. Regularly revisit your models to identify opportunities for optimization. For example, you may find that:
Some data relationships no longer hold.
New data sources need to be integrated.
Performance bottlenecks arise as the system grows.
A proactive approach to refinement not only ensures the longevity of your model but also maximizes performance and adaptability over time.
5. Leverage version control for your models
Version control isn’t just for code — it’s just as essential for managing changes to your data models. Implementing version control allows you to:
Track changes over time, ensuring that you can revert to a previous version if needed.
Collaborate with other data engineers without the risk of overwriting each other’s work. Maintain transparency in terms of who made what changes, and why.
Version control tools like Git are an invaluable asset for managing complex data models, especially in collaborative environments.