


Data engineering, at its core, is about architecting systems that can not only handle the volume, variety, and velocity of data but also deliver insights with precision and speed. As we unpack the essence of what constitutes best practices in data engineering, we do so with an eye towards the tangible impact these practices have on day-to-day operations and long-term strategic goals.
From the intricacies of schema design to the nuances of data pipeline orchestration, we’ll navigate the full gamut of techniques that fortify the backbone of data architecture. These best practices are distilled from years of frontline experience, trial and error, and the shared successes of data engineers who’ve turned challenges into benchmarks for industry excellence.
Data Modeling and Schema Design
Data Modeling and Schema Design are central to the practice of data engineering, creating the structures that hold and relate the data within our systems. The process starts with a deep understanding of the underlying data model of the application or business process. This is critical because it dictates how the schema should be structured to best represent the data and its relationships, and it involves identifying all the entities involved, their attributes, and the connections between them. For example, in an e-commerce system, understanding the relationships between customers, orders, and products is key.
When designing data models, one can use different techniques like network modeling, which focuses on object interrelations and is particularly flexible, or entity-relationship modeling, which helps in defining entities and their relationships within a database. Both approaches offer a way to create a visual representation of data structures, which is essential in planning the actual database schema.
In a real-world scenario, data engineers might be tasked with designing a schema for an organization where multiple departments have overlapping data access needs. Using entity-relationship diagrams (ERDs) can help visualize complex relationships, such as employees who may work in multiple departments or products that fall into multiple categories.
Best practices in data modeling and schema design include:
Detailed upfront planning to make future processes easier and smoother.
Using standardized data schemas to create common denominators that can be transformed for specific analytical needs.
Adhering to clear and consistent naming conventions to avoid confusion and errors in data handling.
Implementing security by design to ensure that data is protected from the outset.
For instance, when designing a schema that will be used by various stakeholders, using clear and consistent naming conventions for tables and fields can make the database more accessible and reduce errors in data handling.
When it comes to interviewing for a data engineering position, you might encounter questions such as:
Can you describe the process you would use to design a schema for a multi-tenant application where different users need to access common data sets?
How would you approach the normalization of a database schema in a legacy system where performance is currently an issue?
Interviewers ask these kinds of questions to gauge your understanding of the fundamental principles of data modeling and schema design, and your ability to apply them to real-world problems. They want to see not only your technical knowledge but also your thought process and how you approach solving complex data challenges. Sign Up and find out more interview questions.
ETL Design and Development
Real-world examples often involve automating data processing for efficiency, troubleshooting data quality issues, optimizing data pipelines for maximum throughput, scheduling ETL tasks to ensure timely data availability, and establishing governance structures to maintain compliance and data integrity.
Design patterns play a crucial role in ETL development. They can range from simple single-step transformations to complex multi-stage processes. For example, batch processing is used when data accumulates over time and is processed in intervals. In contrast, stream processing deals with data in real-time as it’s generated, which is particularly pertinent for continuous data sources like IoT devices.
ETL is more than a technical process; it’s an embodiment of organizational data policy. As such, careful planning, thorough documentation, and clear visualization of the ETL process are key to successful implementation. This encompasses creating detailed data flow diagrams and design documents that outline source and target systems, transformations, quality assurance measures, testing approaches, and automation strategies.
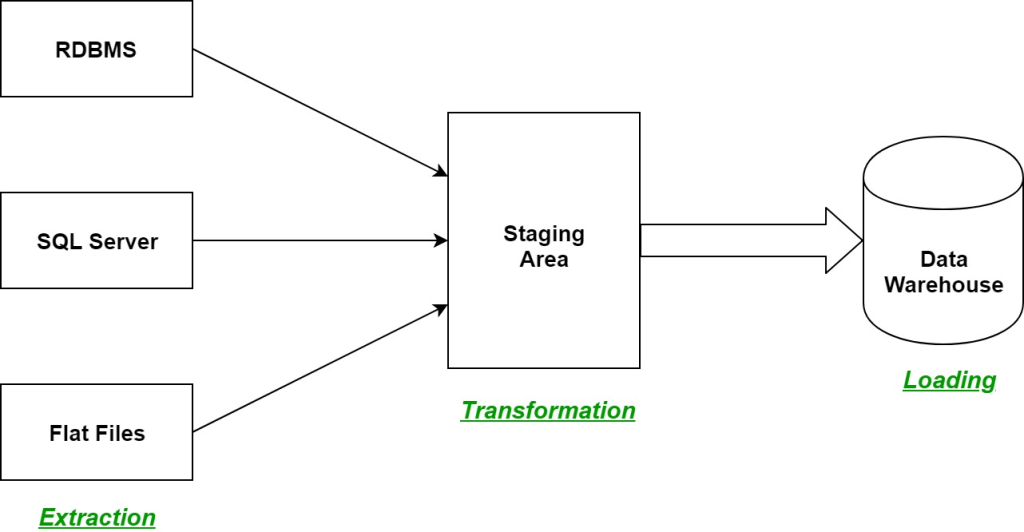
ETL Process in data warehouse. Image source.
Interview Questions Examples:
In an interview setting, you may be asked to describe how you would handle specific challenges encountered during ETL processes. For instance:
Describe a time you optimized a batch processing ETL task to handle a high volume of data.
How have you managed real-time data streams in an ETL pipeline, and what tools did * you use?
Can you walk us through your approach to documenting ETL processes within your organization?
Give an example of how you have used ETL design patterns to improve data processing efficiency.
In tackling these questions, showcasing your understanding of various ETL patterns and your ability to apply them effectively to solve problems will demonstrate your capability as a data engineer. Emphasize your experience in automating processes, streamlining data transformations, and ensuring that the ETL design is not only compliant with organizational standards but also aligned with broader business objectives.
Data Engineer Academy offers a variety of courses that cover essential concepts and provide real-world ETL practice scenarios. The best part? You can start for free now.
Data Storage Solutions
Real-world Examples of Data Storage Solutions:
File Storage – utilized for organizing data hierarchically in files and directories. It’s suitable for scenarios where data is accessed and managed as individual files. This traditional form of storage is common in everyday computing environments.
Block Storage – ideal for scenarios requiring high performance, such as database storage or applications needing rapid, efficient, and reliable data transport. Each storage block acts independently, allowing for versatile use across different settings.
Object Storage – designed to manage massive volumes of unstructured data, object storage solutions like Google Cloud Storage, Amazon S3, and Azure Blob Storage provide scalable, secure environments for storing photos, videos, and other multimedia files. It’s particularly favored in web-based applications for its ability to handle data at scale.

Amazon S3 Objects Storage
Interview Questions Examples:
- How would you decide between using a data lake versus a data warehouse for a particular use case?
This question tests your understanding of data storage concepts and your ability to apply them to specific business needs. A good answer would outline the differences in use cases for data lakes and warehouses and discuss factors like data structure, processing needs, and performance requirements.
- Can you describe a scenario where object storage would be more beneficial than block storage, and why?
Here, the interviewer is looking for your knowledge of the characteristics and advantages of object storage, such as scalability and managing unstructured data, compared to the more traditional block storage, which is often used for databases and high-performance applications.
- What considerations would you take into account when setting up a hybrid cloud storage solution?
This question assesses your ability to integrate various storage solutions to meet complex requirements. Discuss considerations like data security, compliance, cost, access speed, and how different types of data might be better suited to private or public cloud storage.
Building Resilient Data Pipelines
A resilient data pipeline can handle failures gracefully, scale according to demand, and recover from disruptions without data loss or significant downtime.
Real-world Examples of Resilient Data Pipelines
Financial Transaction Processing – in financial services, a resilient data pipeline might be employed to process transactions in real-time. For example, a bank might use a pipeline that not only handles millions of transactions daily but also incorporates mechanisms for fraud detection. This pipeline must be capable of quickly recovering from any failure to prevent financial loss or data breaches.
E-commerce Inventory Management – e-commerce platforms often rely on data pipelines to manage inventory levels in real-time across multiple warehouses. A resilient pipeline ensures that inventory data is always accurate and up-to-date, even in the face of network failures or spikes in user demand during sales events.
Streaming Data for Real-time Analytics – companies like Netflix or Spotify process streaming data from millions of users to offer personalized content recommendations. These pipelines are designed to be resilient, ensuring that data processing continues smoothly despite the huge volumes of incoming data streams.
See below for a SQL interview question from Spotify:
Find the names of users who have listened to songs for four consecutive days in the current week
user_id | 1629 |
name | Arthur Taylor |
city | NY |
dim_users_spotify
user_id | 1552 |
song_id | 332 |
song_plays | 16 |
fact_historical_songs_listens
listen_id | GB45FWJG44006503379431 |
user_id | 1949 |
listen_time | 2022-11-9 15:00:00 |
fact_weekly_songs_listens
Interview Questions Examples
- Describe an experience where you had to improve the resilience of an existing data pipeline. What challenges did you face and how did you overcome them?
This question assesses your problem-solving skills and understanding of data pipeline resilience. A strong answer would detail specific challenges, such as handling data volume spikes or minimizing downtime, and the strategies implemented to address these issues, such as introducing automatic scaling or failover mechanisms.
- How do you ensure data integrity and prevent data loss in your data pipelines?
Here, interviewers are looking for your knowledge of techniques and tools for data validation, error handling, and recovery. Mention practices like implementing checkpoints in the data flow, using transaction logs, or employing data replication strategies.
- Can you explain how you would design a data pipeline for real-time processing of streaming data? What considerations would you take into account to make it resilient?
This question probes your ability to apply resilience principles to the design of real-time data processing systems. Discuss considerations such as low-latency processing, scalability to handle varying data volumes, and mechanisms for dealing with incomplete or out-of-order data.
Performance Tuning and Optimization
Techniques for Optimizing Data Storage and Retrieval
Creating materialized views is a powerful optimization technique for data storage and retrieval in Snowflake. Materialized views are best used when query results don’t change often but are queried frequently, and the query itself is resource-intensive. By storing query results, materialized views speed up data retrieval but at a cost of increased storage and compute resources during automatic background maintenance to keep them up-to-date. When choosing between materialized views and regular views, consider the frequency of data changes, query execution costs, and how often the data is accessed.
Additionally, leveraging Snowflake’s search optimization service can drastically improve the performance of selective point lookup queries. This service is especially beneficial for business users and data scientists who need fast access to data for critical dashboards or specific data subsets exploration. By adding search optimization to a table, Snowflake enhances the efficiency of data retrieval for supported data types.
Query Performance Tuning and Resource Optimization
In distributed data systems like Snowflake, utilizing data streaming options, such as the Snowflake Kafka Connector or Snowpipe, facilitates efficient data ingestion directly from streaming sources, enabling real-time data processing and analysis. Snowpipe, for example, offers a serverless process to load data files as they arrive in cloud storage, automatically scaling compute resources as necessary.
For data transformation within Snowflake, multiple options exist, ranging from using ETL tools that follow the pushdown principle, leveraging stored procedures for complex logic, to employing Snowflake Streams and Tasks for near real-time processing. These transformation options showcase the versatility of Snowflake in handling various data engineering tasks, from simple to complex, with efficiency and scalability.
When building resilient and high-performing data pipelines or storage systems, it’s critical to choose the right tool for the task at hand, considering the unique benefits and costs associated with each optimization technique.
The decision-making process should be informed by the specific requirements of the data workload, including volume, velocity, and variety, as well as the overarching goals of the data architecture.
FAQ
Q: What are the foundational skills for a data engineer?
A: Data engineering requires a mix of software engineering skills and knowledge of database systems. Proficiency in programming languages such as Python or Java, understanding of SQL and NoSQL databases, experience with ETL tools, and familiarity with big data technologies like Hadoop or Spark are crucial.
Q: How can data modeling and schema design impact data system performance?
A: Effective data modeling and thoughtful schema design are critical for optimizing data storage and retrieval, ensuring data integrity, and supporting scalable growth. Well-designed schemas reduce data redundancy, improve query performance, and facilitate easier maintenance.
Q: What’s the significance of ETL processes in data engineering?
A: ETL processes are essential for preparing raw data for analysis. By extracting data from various sources, transforming it into a structured format, and loading it into a data warehouse, ETL processes make data more accessible and useful for business intelligence and analytics.
Q: Why is monitoring and optimizing data pipelines important?
A: Monitoring data pipelines helps identify performance bottlenecks, data inconsistencies, and failures in real-time. Optimization ensures that data flows efficiently through the pipeline, enhancing system performance and reducing costs associated with data processing and storage.
Q: How do you ensure data quality in a data engineering project?
A: Ensuring data quality involves implementing validation checks, data cleansing processes, and consistent schema enforcement. Regular audits and monitoring for data anomalies also contribute to maintaining high data quality.
Q: What are some best practices for data security in data engineering?
A: Data security best practices include encrypting data at rest and in transit, implementing access controls and authentication mechanisms, maintaining data privacy standards, and adhering to compliance regulations specific to the industry.
Q: How can data engineers stay updated with the latest trends and technologies?
A: Data engineers can stay updated by following industry blogs, participating in online forums and communities, attending conferences and webinars, and continuously exploring new tools and technologies through hands-on projects.